Kodowanie Huffmana
Polega ono na zastępowaniu symboli występujących w strumieniu wejściowym specjalnymi sekwencjami bitów stanowiących tzw. słowa kodowe. Słowa kodowe dobiera się w taki sposób, by najkrótsze z nich przyporządkować symbolom najczęściej występującym w strumieniu wejściowym, a najdłuższe symbolom o najniższych częstotliwościach wystąpień. Ponadto żadna sekwencja bitów nie może być przedłużeniem innej, co zapewnia jednoznaczność pomiędzy reprezentacją naturalną a zbiorem danych przedstawionym w postaci zakodowanej. Dzięki swej konstrukcji kody Huffmana znajdują szerokie zastosowanie w bezstratnej kompresji danych, w szczególności tam, gdzie występują znaczne różnice pomiędzy częstotliwościami wystąpień symboli, a słaba korelacja pomiędzy sąsiednimi elementami wyklucza użycie metod słownikowych. Stąd kody Huffmana stosuje się powszechnie w formatach kompresji obrazu i dźwięku, np. JPEG, MPEG oraz MP3.
Klasyczny algorytm wyznaczania słów kodowych bazuje na drzewie binarnym. Załóżmy, że w strumieniu wejściowym występują 8-bitowe liczby całkowite, tzn. dane typu "unsigned char". Niech przykładowy ciąg symboli do zakodowania przyjmie następującą postać:
- Zliczamy częstotliwości wystąpień poszczególnych symboli tworząc tzw. las, w którym każde drzewo (tutaj posiadające tylko jeden węzeł) zawiera jeden symbol oraz wagę będącą liczbą wystąpień danego symbolu.
-
Następnie z lasu utworzonego w punkcie 1 wybieramy dwa drzewa o najniższych wagach i
łączymy je, tworząc nowe drzewo o wadze będącej sumą wag drzew składowych. Operację
tę powtarzamy aż do uzyskania jednego drzewa. Dla naszego przykładu mamy:
- krok
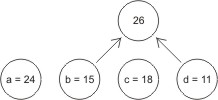
- krok
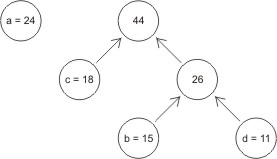
- krok
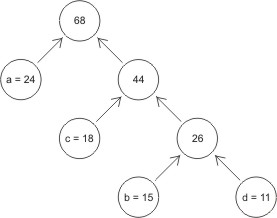
- krok
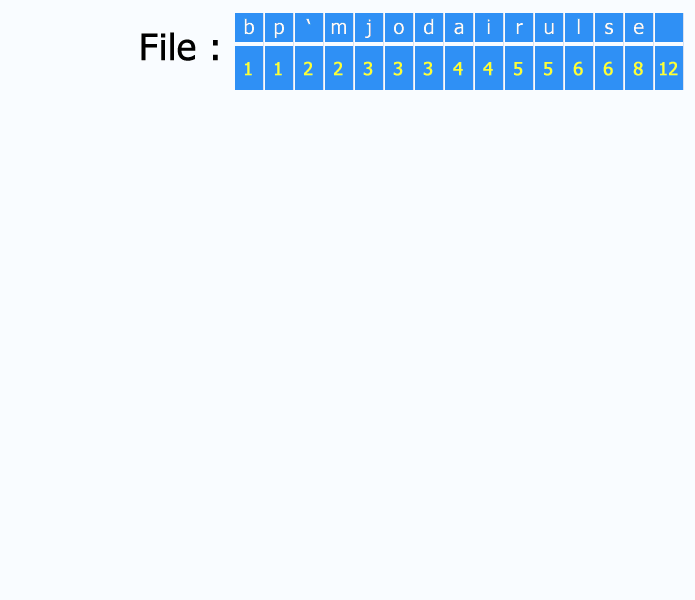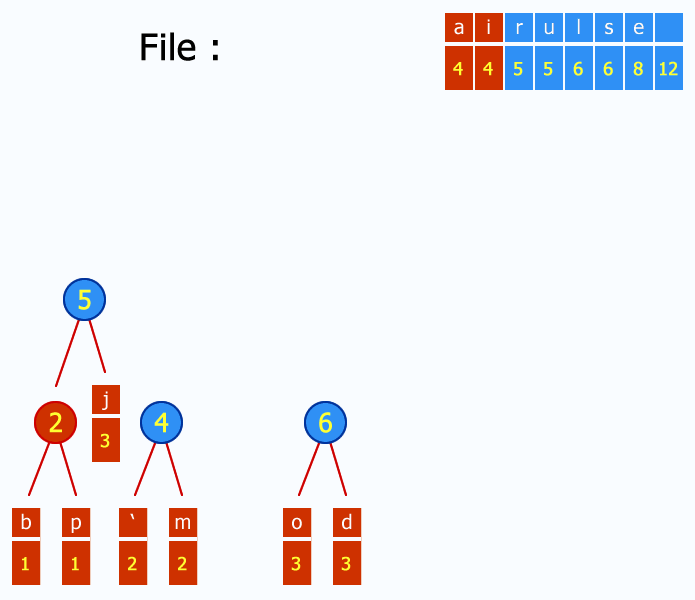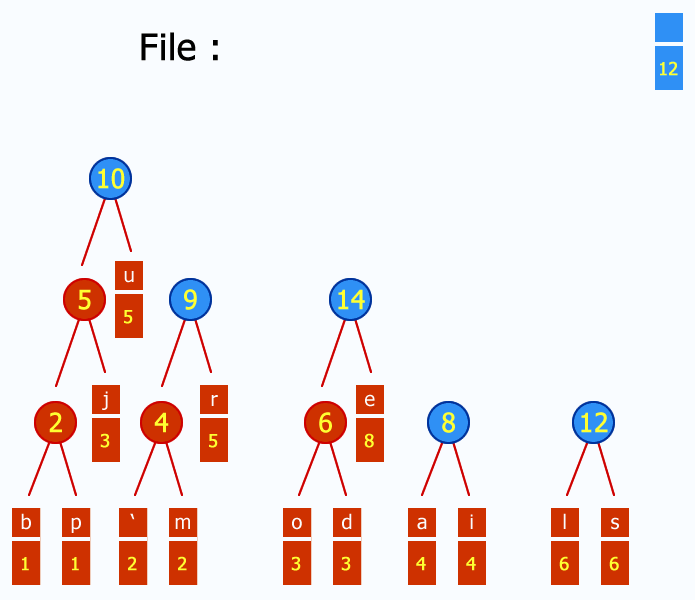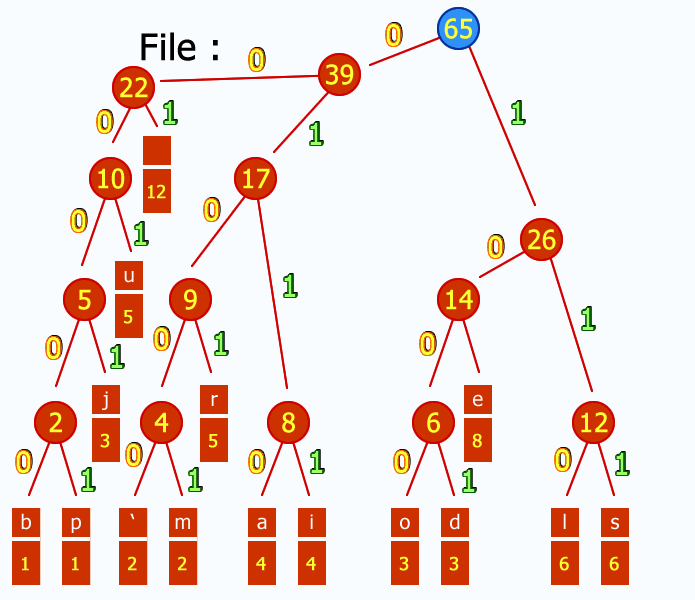
- Następnie dla każdego symbolu wyznaczamy słowo kodowe, będące ścieżką od korzenia do liścia zawierającego dany symbol, przy czym przejściu w lewo przyporządkowujemy bit '0' a przejściu w prawo bit '1'. W naszym przykładzie po przyjęciu tej zasady drzewo kodów Huffmana przyjmie postać:

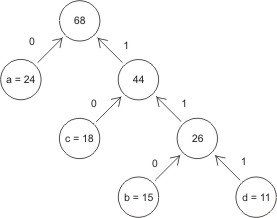
| a | 0 |
|---|---|
| c | 01 |
| b | 011 |
| d | 111 |
a a a d d d c b b c c c b ... 0 0 0 111 111 111 01 011 011 01 01 01 011 ... czyli 00011111111101011011010101011...Przykład drzewa z: http://en.wikipedia.org/wiki/File:Huffman_huff_demo.gif#filehistory
dla: "j'aime aller sur le bord de l'eau les jeudis ou les jours impairs"